수강 후기
데이터리안 SQL 데이터 분석 캠프 실전반 과정이 모두 끝났습니다.
데이터 분석가 직무를 준비하는데 많은 도움이 될 것 같아서 시작하였고,
실제로 많은 인사이트를 얻어갈 수 있었다고 생각합니다.
4Ls로 캠프의 후기를 구체적으로 남겨보려고 합니다!
1) Liked: 좋았던 점
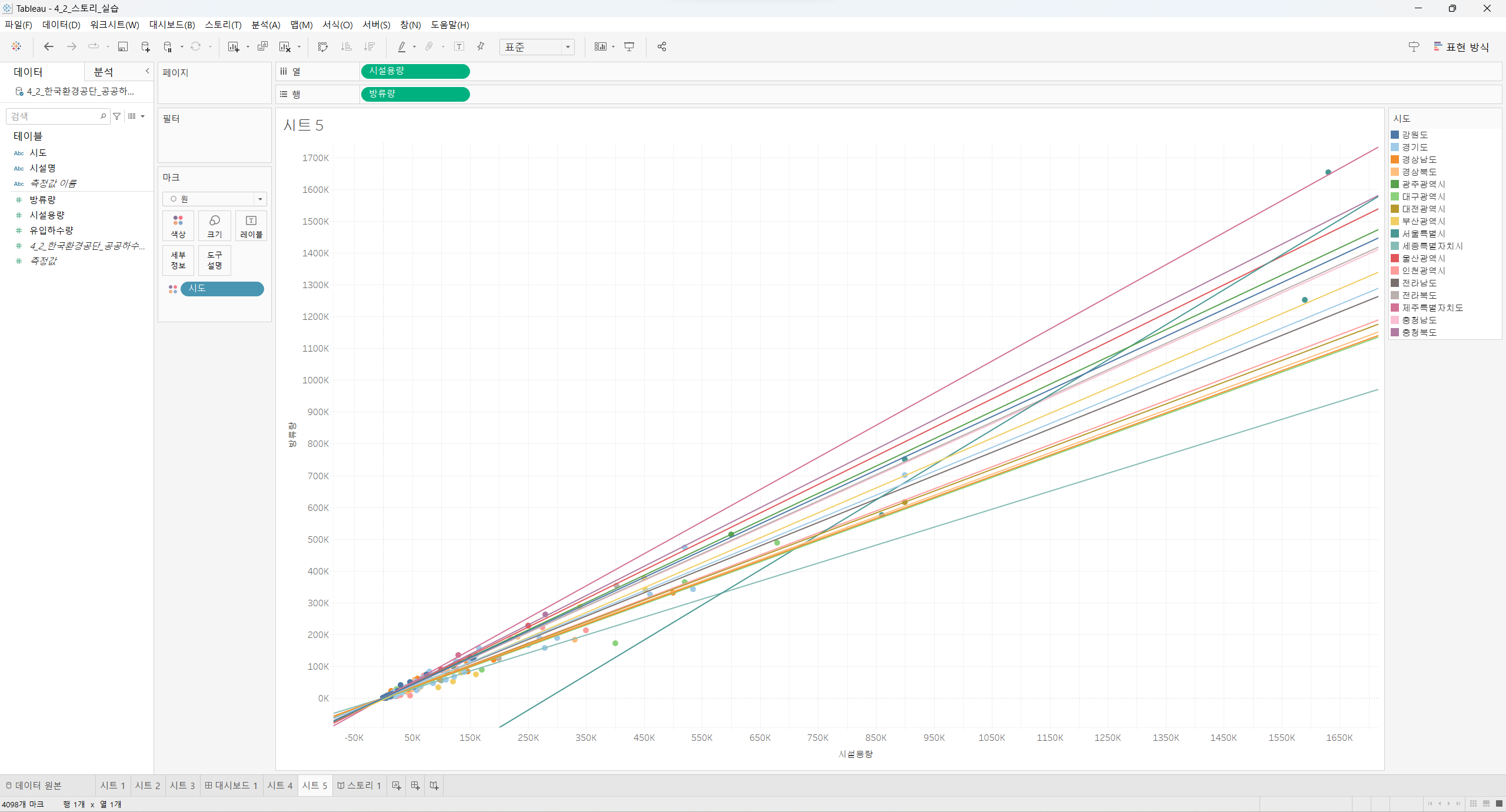
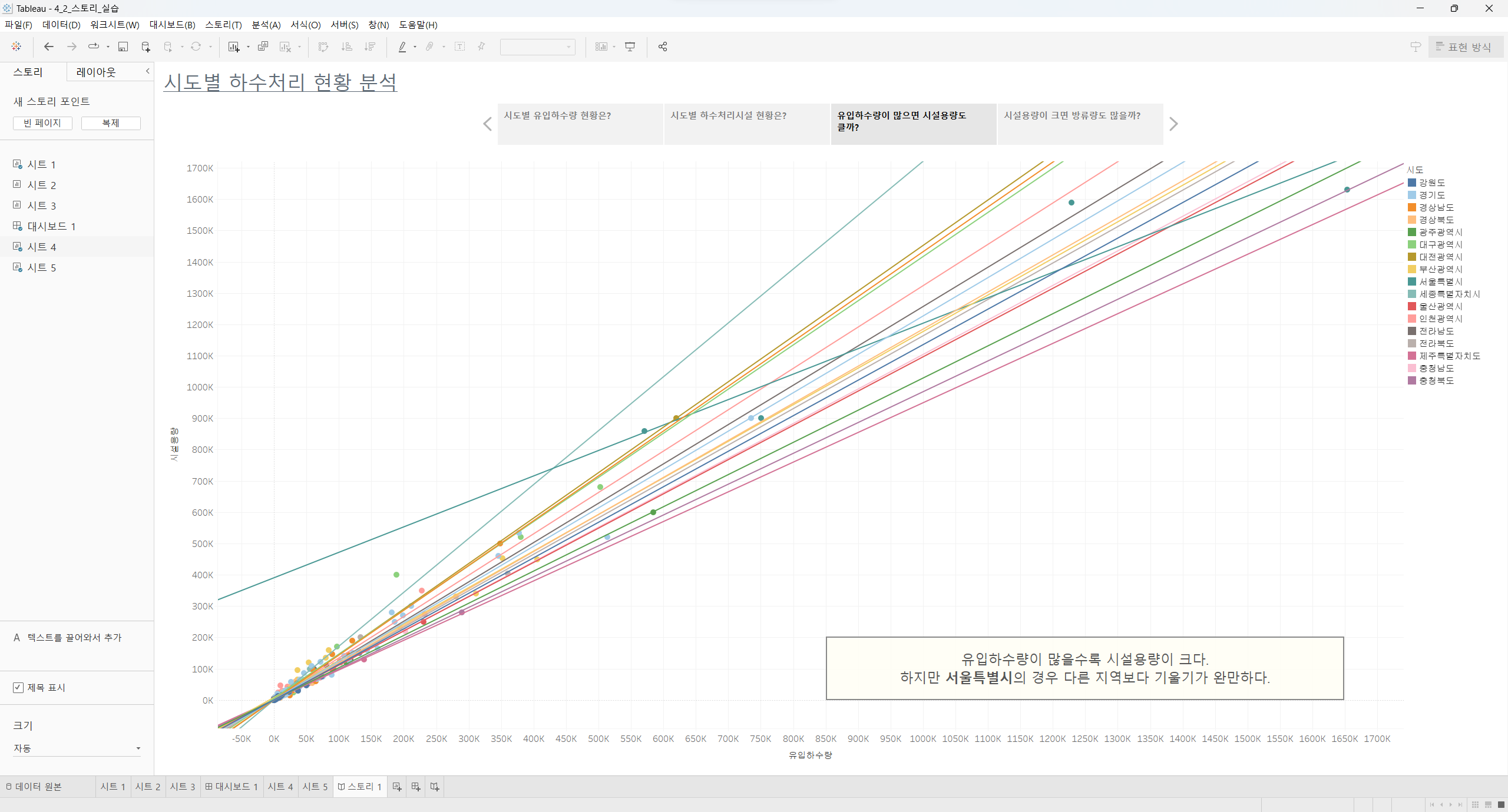
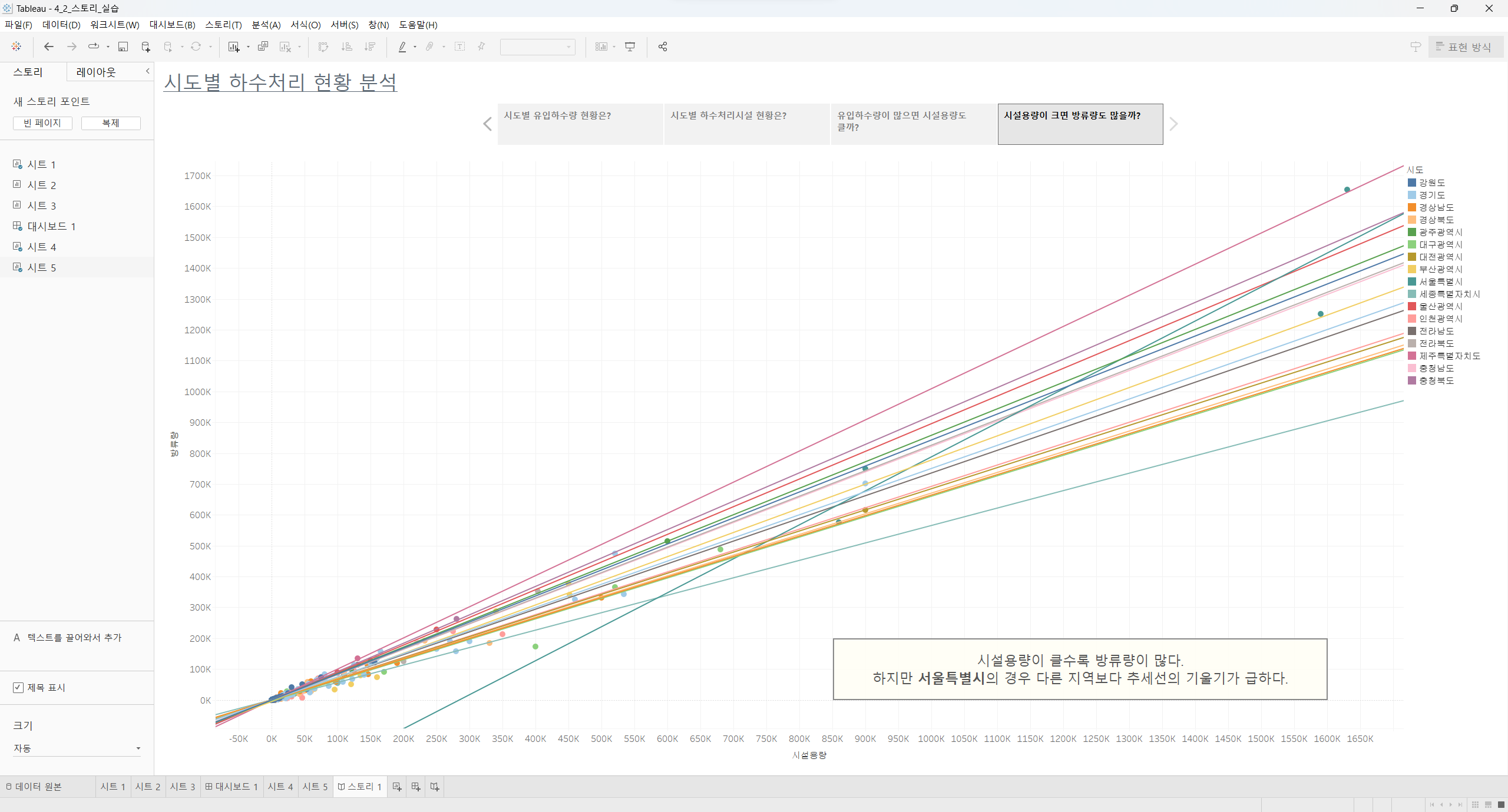
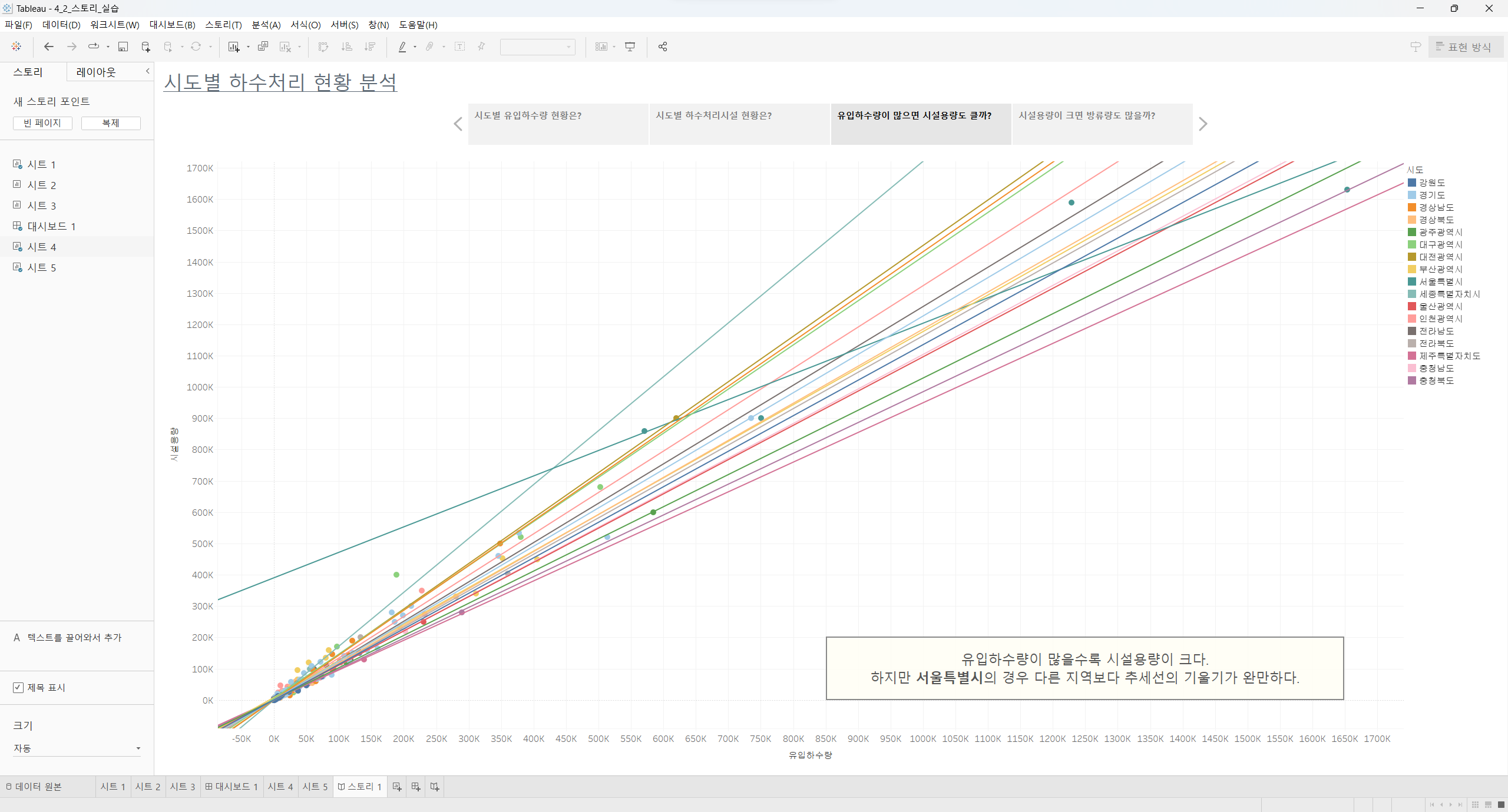
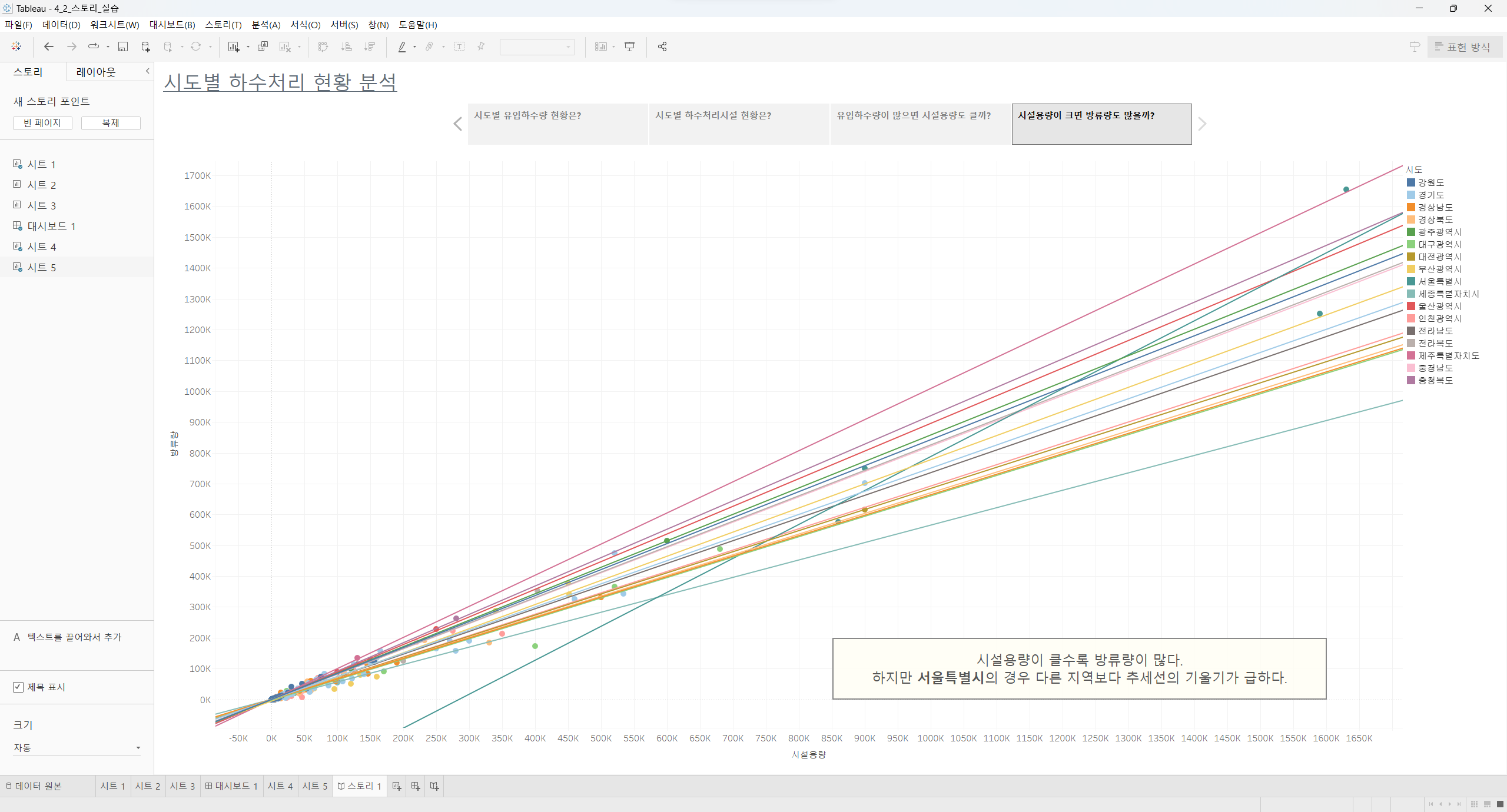
리텐션 분석, 퍼널 분석 등 실무에서 다루는 분석을 하는 법을 배우는 과정이 있습니다.
제가 '데이터리안'이라는 회사에 재직 중인 데이터 분석가인 것처럼
'데이터리안'의 사용자 로그 데이터를 활용해서 다양한 분석을 경험을 해볼 수 있었던 점이 가장 좋았습니다.
2) Lacked: 아쉬웠던 점
이미 수집되어 있는 데이터와 주어지는 문제 하에서 다양한 분석을 경험해 볼 수 있어서 좋았지만,
데이터를 수집하는 과정 그리고 어떤 문제가 있는지 정의하고 해결하는 과정을
직접 경험해볼 수는 없어서 이 부분이 가장 아쉬웠습니다.
하지만, 이 부분을 캠프 안에서 다루기엔 다양한 문제 상황들이 있을 거라고 생각하고,
추가적인 공부를 통해 부족한 부분을 채워나가면 된다고 생각합니다. 😁
3) Learned: 배운 점
SQL 데이터 분석 전반에 있어서 중요하고 필요한 내용만 담은 알짜배기 교육이었다고 생각합니다!
서브쿼리, 윈도우함수 등 효율적인 쿼리문을 구성할 수 있는 SQL 응용 문법,
실무에서 일어나는 분석을 직접 경험해 볼 수 있는 리텐션 분석, 퍼널 분석,
데이터리안의 데이터 분석가가 되어서 전반적인 분석 과정을 실습해 보는 서비스 이용 패턴 분석을
배울 수 있었습니다.
4) Longed for: 앞으로 바라는 점
여러 데이터 분석 프로젝트를 경험해보면서
기업의 데이터를 얻기 힘들기 때문에 공공데이터를 활용한 사회 문제를 주제를 주로 해결해야 한다는 점,
분석 결과 도출한 개선점을 직접 적용해 볼 수 없기 때문에 실제로 문제가 개선되었는지 확인할 수 없다는 점이
항상 아쉬웠고 한계점으로 남아있었습니다.
따라서 데이터리안의 데이터를 이용한 데이터리안의 문제를 해결하기 위한 내부 공모전을 진행하고
가장 우수한 팀의 결과를 직접 적용해 보고 성과를 점검할 수 있는 기회를 얻을 수 있는!
이러한 형태의 의미 있는 프로그램이 있다면 많은 도움이 되지 않을까 생각해 봅니다. 😲
데이터리안 SQL 데이터 분석 캠프 실전반 수료증